Posted on: Dezember 16th, 2024 by Frank Wöhrle No Comments
Schon wieder ist ein Jahr vorbei, und wir können selbst kaum fassen, wie schnell die Zeit verflogen ist. Ein guter Zeitpunkt, um alle wichtigen Entwicklungen aus dem KI-Jahr 2024 Revue passieren zu lassen und Ihnen einen Ausblick auf das kommende Jahr zu geben.
Seitdem OpenAI die Welt mit ChatGPT in Staunen versetzt hat, ist das Thema KI geradezu explodiert. Unternehmen drängen zunehmend darauf, KI überall dort einzusetzen, wo es möglich erscheint. Aus den zahlreichen Diskussionen und spannenden Kundenprojekten dieses Jahr haben wir zentrale Learnings und Trends in diesem Bereich erkannt.
Fünf wichtige Trends beim Einsatz von KI im Kontext der Übersetzung
Die Erwartungen an generative KI sind nach wie vor sehr hoch. Dabei werden die die Einsatzmöglichkeiten gerade in Sprachprozessen jedoch immer differenzierter betrachtet: Von der Wunschvorstellung einer Wundermaschine, die Texte perfekt erstellt, übersetzt und optimiert, hin zu einem smarten Helferlein, das gezielt bei Aufgaben unterstützt, bei denen heutzutage manuelle Aufwände anfallen. Die immer stärkere Integration großer Sprachmodelle in die Übersetzungsprozesse macht genau das möglich, indem sie gezielt und modular unterstützt, sei es bei der zweisprachigen Extraktion von Terminologie, dem Post-Editing von maschinell erstellten Übersetzungen oder der Qualitätsbewertung von mehrsprachigen Dokumenten.
Wer die Technologie effizient und nachhaltig einsetzen möchte, der benötigt auch qualitativ hochwertige, gut strukturierte Sprachressourcen, um die Sprachmodelle mit relevanten Informationen versorgen zu können. Das heißt, dass sich die jahrelange Arbeit mit Translation Memory- und Terminologieverwaltungssystemen nun gleich doppelt auszahlt. Werden diese Daten strukturiert und nachhaltig aufbereitet, können Sprachmodelle sie zur Optimierung von maschinellen Übersetzungen verwenden, etwa in Form der sogenannten Retrieval-Augmented Generation (RAG).
Das Thema Datenschutz sorgt trotz der Verabschiedung des EU AI Actim Mai 2024 nach wie vor für große Unsicherheit. Viele Unternehmen suchen nach Wegen, wie KI auf möglichst sichere Weise eingesetzt werden kann, um ihre wertvollen Daten vor Missbrauch zu schützen.
Viele Unternehmen sehen Schwierigkeiten bei der Skalierbarkeit von KI-Lösungen, sei es in Bezug auf die IT-Infrastruktur, finanzielle Ressourcen oder die Weiterbildung ihrer Mitarbeiter*innen.
Human in the Cockpit – Menschen werden stärker ins Zentrum der KI-basierten Übersetzungsworkflows rücken. Waren Übersetzer*innen bisher in Form des Human in the Loop etwa für das Post-Editing vordefinierter maschineller Übersetzungen zuständig, soll der neue Human in the Cockpit moderne Sprachtechnologien selbst interaktiv einsetzen können, um individuell Einfluss auf den Output nehmen und Prozesse effizient gestalten zu können. Durch den technologischen Wandel ändern sich auch die Anforderungen an heutige und zukünftige Sprachexpert*innen. Diese Entwicklung erkennen auch die einschlägigen Hochschulen und passen ihre Studiengänge und Kursangebote entsprechend an. So sind Prompt Engineering, Sprachtechnologien oder Informationsmanagement wichtige Schwerpunkte, die wir künftig häufiger auf den Lehrplänen zu sehen bekommen werden.
Sie finden dieses Thema spannend? Dann freuen Sie sich auf unser für Anfang 2025 geplantes STAR-Webinar. Darin informieren wir Sie über aktuelle Trends und unsere neuesten technologischen Entwicklungen.
Posted on: Oktober 28th, 2024 by Frank Wöhrle No Comments
Kann die KI helfen, hochwertige Inhalte in jeder Sprache zu erstellen und dabei Unternehmenssprache und Besonderheiten einhalten?
Heute führen wir ein Interview mit David Heider, dem Inhaber eines STAR-Partner-Tonstudios in Tschechien, um diese spannende Frage zu beleuchten: Kann die künstliche Intelligenz im Bereich der Video- und Audio-Produktionen effizient eingesetzt werden?
STAR: David, seit wann bietet ihr professionelle Audioproduktionen an?
Unser Tonstudio bietet seine Dienste seit 1999 an, und wir haben uns auf das gesprochene Wort spezialisiert. Wir decken zwei verschiedene Bereiche ab: erstens die „Unternehmenswelt“ mit Aufzeichnungen von Material für interne Zwecke wie E-Learnings. Dazu gehört auch die Lokalisierung von unternehmensinternen Systemen und Software. Das können entweder Schulungsmaterial oder verschiedene webbasierte Plattformen mit Sprachausgabe sein oder automatische Operatoren auf Ihrem Telefon, Navi usw. – kurz gesagt, verschiedene Anwendungen, bei denen wir den Ton häufig wortweise oder sogar Silbe für Silbe schneiden müssen und wo anschließend alles von einem System zu Sätzen und ganzen Nachrichten zusammengesetzt wird.
Der zweite Bereich bewegt sich mehr im künstlerischen Umfeld und umfasst u.a. Werbung und Werbevideos. Dieser unterscheidet sich von der erwähnten „Unternehmenswelt“ dadurch, dass es nicht nur um die Vermittlung von Inhalten geht, sondern vielmehr um eine Form, die Zuhörende ansprechen und attraktiv auf sie wirken soll. Wir brauchen hier also Profis, die sich künstlerisch ausdrücken und ihre Stimme gekonnt einsetzen können. Zusammenfassend lässt sich sagen, dass unser erster Aktionsbereich vor allem der Information dient. Hier geht es um Inhalte, wo die Nutzenden, um es etwas deutlicher zu sagen, keine große Wahl haben, da sie in der Regel zuhören müssen. Dahingegen zielen die künstlerischen Produktionen darauf ab, das „Publikum“ in irgendeiner Weise zu verführen, und zwar nicht nur inhaltlich, sondern auch formal.
STAR: Dies führt mich zwangsläufig zur nächsten Frage: Kann KI bei eurer Arbeit eingesetzt werden?
Die KI ist ein erstaunliches Werkzeug und bietet zahlreiche Vorteile. Wir brauchen uns zum Beispiel nicht mit einem Sprecher oder einer Sprecherin in Verbindung setzen und einen Termin vereinbaren; die KI ist jederzeit erreichbar.
STAR: Setzt ihr bereits KI ein?
Ja. Für die Aufbereitung und Produktion von Audio-Material setzen wir z.T. KI ein. Das Ganze hat aber auch eine Kehrseite. In den meisten Sprachen wirkt die KI -Stimme künstlich oder langweilig, vor allem nach längerem Hören.
STAR: Kann KI nicht intonieren?
Intonieren an sich ist meist nicht das Problem, aber bei der KI passiert das leider stereotyp, was wirklich ungünstig ist. Oft wird die Kernbotschaft nicht unterstrichen, die ein Mensch ja im Normalfall durch besondere Betonung ausdrückt. Und wenn man sich eine KI-Aufnahme anhört, hat man dieses sich wiederholende Klischee im Ohr, das mit der Zeit beginnt zu nerven, da man das Gefühl nicht los wird, dass es eigentlich nur „Copy-Paste“ ist. In der englischen Sprache finde ich es im Vergleich deutlich besser als in anderen Sprachen, da kann die KI mit variabler Intonation arbeiten und die Stimme sehr natürlich und lebendig wirken lassen, aber bei allen anderen Sprachen haben wir noch einen weiten Weg vor uns, bis das passiert. Aktuell klingen die anderen Sprachen noch sehr „plastisch“.
STAR: Gibt es weitere Nachteile von KI-Stimmen?
Es gibt noch einen zweiten Punkt, der meiner Meinung nach schwerwiegender ist, insbesondere beim E-Learning. Wie bei jeder KI hängt die Qualität des Ergebnisses von der Qualität des Inputs ab. Auch bei der Stimme muss man immer den Inhalt richtig vorbereiten. Vielleicht liest die KI nicht alle Abkürzungen richtig, wie sie in einer bestimmten Unternehmenskultur gelesen werden. Jedes Unternehmen hat einen bestimmten Firmenjargon, und die KI wird dies nicht berücksichtigen. Dies gilt auch für unterschiedliche Produktnamen, Ortsnamen oder Fremdwörter. Wenn im Englischen zum Beispiel französische Namen auftauchen, stellt sich die Frage, ob sie auf Französisch oder Englisch gelesen werden.
STAR: Wie lässt sich das erklären?
Nur die Mitarbeitenden eines Unternehmens sind mit der Unternehmenssprache wirklich vertraut und wissen, weshalb manchmal aus unternehmensinternen oder Marketing-Gründen von einer Sprachregel abgewichen wird. Die Hörenden sind Insider, d. h. sie wissen in der Regel Bescheid. Und die Unternehmen müssen konsequent sein, denn sonst klingt es in ihren Ohren fremd. Manchmal kann ein Begriff oder eine Abkürzung natürlich falsch verstanden werden, entweder phonetisch oder in Bezug auf den Namen, aber das ist einfach die Art und Weise, wie es in dem Unternehmen gemacht wird, und wir sollten es respektieren.
STAR: Welche weiteren Herausforderungen gibt es?
Abkürzungen und andere Besonderheiten sind eine große Herausforderung für die KI. Sie erfordern meistens viele Anpassungen und Korrekturen, was dazu führen kann, dass der Endpreis ähnlich hoch ist wie bei einem klassischen Voice-Over. Wir müssen einen Aussprachehinweis erstellen oder den Text so bearbeiten, dass er für die KI gut lesbar ist. Dies ist sehr zeitaufwendig, daher ist KI für ein einmaliges Projekt wenig sinnvoll. Darüber hinaus führen wir nach der KI zusätzlich ein Proof-Listening durch, d. h. ein Check-Listening.
STAR: Macht ihr bei menschlichen Sprecher*innen kein Proof-Listening?
Wenn wir bei der Aufnahme zusätzlich zum Sprecher oder zur Sprecherin zu zweit sind, machen wir das nicht mehr, weil wir während dieser Aufnahme alles hören und prüfen können. Die Ausnahme bilden Sprachen, die wir nicht verstehen, wie z. B. asiatische Sprachen. Aber im Falle der KI wissen wir nicht im Voraus, was sie weiß und lesen kann. Ich gebe Ihnen ein Beispiel: Nehmen Sie die Einheit „Megapascal“, abgekürzt mit „MPa“. Die KI kann sie als „em-pee-ah“ lesen, was für eine*n Techniker*in völliger Unsinn ist. Wir müssen also herausfinden, wie wir sie dazu bringen können, es richtig als „Megapascal“ zu lesen.
Manchmal kommt es vor, dass wir die Aufnahme durchgehen, sie uns richtig erscheint, aber dann findet der Kunde etwas, das nicht zu seiner Unternehmenskultur passt. Deshalb denke ich, dass KI zwar in bestimmten informativen Texten ein nützliches Werkzeug ist, das die Arbeit schneller und billiger machen kann, und ich empfehle es gerne, aber in den Händen eines unerfahrenen Benutzenden kann sich die KI sich unvorhersehbar verhalten, und das Endprodukt wird mehr Enttäuschung als Begeisterung über die eingesparten Ressourcen hervorrufen.
STAR: Gibt es einen finanziellen Unterschied?
Ja, durch den Einsatz von KI sinkt das Budget auf etwa die Hälfte oder zwei Drittel, da die Arbeit hauptsächlich von einer Maschine erledigt wird und keine Sprechprofis in den Prozess eingebunden sind.
STAR: Wie geht ihr vor, wenn eine Aufnahme nicht für KI geeignet ist?
Wir sind der Garant für Qualität, und wenn wir ernsthafte und berechtigte Zweifel daran haben, dass KI zum richtigen Ergebnis führt, informieren wir den Kunden. Kunden möchten aber auch persönliche Erfahrungen machen. Ich versuche dann zunächst, darauf hinzuweisen, nach dem Motto: „Seien Sie nicht enttäuscht, aber ich denke, dass KI für dieses spezielle Projekt nicht geeignet ist.“ Wenn ich das Gefühl habe, dass ich alles beschrieben habe, überlasse ich ihnen die Entscheidung. Aber in manchen Fällen ist sich der Kunde selbst unsicher und nimmt unsere Unterstützung dankbar an.
STAR: Vielen Dank, David, für diese äußerst interessante Diskussion über KI bei Audioaufnahmen.
KI-Stimmen sind noch nicht perfekt, und die menschlichen Stimmen gewinnen immer noch das Rennen. Sie sind in der Lage, Gefühle zu vermitteln und einen starken Eindruck zu hinterlassen. KI-Stimmen sind allerdings eine günstige Alternative. Lassen Sie sich gerne von uns beraten.
David Heider, Inhaber eines STAR-Partner-Tonstudios in Tschechien
Posted on: September 30th, 2024 by Frank Wöhrle No Comments
Seien Sie herzlich willkommen!
Es ist wieder soweit! Vom 5. bis 7. November findet mit der tekom Europas größte Tagung für Technische Kommunikation in Stuttgart statt.
Besuchen Sie uns in Halle C2 am Stand 2D13 und erfahren Sie mehr über unsere Sprachdienstleistungen, Enterprise-Technologien und neuesten Entwicklungen.
Ihr kostenloses Ticket zur tekom-Messe
Wir möchten Sie gerne zur tekom-Jahrestagung einladen. Füllen Sie einfach dieses Formular aus und wir übermitteln Ihnen umgehend Ihren persönlichen Messecode für die Registrierung.
Bitte beachten Sie: Der Messecode ist nur gültig für den Besuch der Messe. Das Messeticket ist nicht gültig für den Besuch der Tagung.
Wir freuen uns, Sie auf den tekom-Veranstaltungen im Oktober/November 2024 begrüßen zu dürfen!
STAR-Vorträge auf der tekom
KI im Content-Recycling: Effizienz und Anpassungsfähigkeit
In der Welt des Component Content Managements kann Künstliche Intelligenz einen Unterschied machen. Hilti, in Zusammenarbeit mit STAR und Amazon Web Services, hat das Claude-3 Modell von Amazon untersucht. Dieser Beitrag zeigt, wie KI die Wiederverwendung von Inhalten verbessern und Fragmente automatisch anpassen kann. Entdecken Sie die praktischen Ergebnisse und die Möglichkeiten für zukünftige Authoring Memories.
In diesem Beitrag erfahren Sie, wie Sie mit KI beim Erstellen der technischen Dokumentation die Wiederverwendung steigern und damit Zeit und Kosten sparen können.
Dominik Faupel (Hilti Entwicklungsgesellschaft mbH) Dr. Matthias Gutknecht (STAR Group) Montag, 28. Oktober, 10:50 – 11:30 Uhr, Online, Technology Days
Sehen und Verstehen: Visuelle Vermittlung von Produktwissen
Visuelle Kommunikation prägt unseren Alltag durch Plattformen wie Snapchat, Instagram, YouTube und TikTok. Studien zeigen, dass Mitarbeiter Aufgaben mit visueller Kommunikation besser ausführen können, schneller arbeiten und weniger Fehler machen. Zudem bleiben visuelle Inhalte bleiben besser im Gedächtnis als Text. Neue Ansätze wie immersive Trainings mit 3D-Modellen und -Animationen sowie visuelle Fernunterstützung gewinnen an Bedeutung und werden in der Präsentation mit kurzen Beispielen vorgestellt. Diese Methoden bieten Vorteile wie standortunabhängiges Lernen und Unterstützung, schnellere Anpassungsfähigkeit und Kosteneffizienz. Visuelles Produktwissen vereinfacht die Arbeitsvorbereitung und -durchführung, reduziert Fehler und ermöglicht weltweite Unterstützung. Ein Anwendungsbeispiel illustriert, wie Virtual Reality Trainings von einem europäischen Unternehmen für weltweite Trainings von Technikern genutzt werden. Zum Schluss wird gezeigt, wie Visualisierungen synchron mit der redaktionellen Inhaltserstellung in der Autorenumgebung erstellt werden können.
Sprachmodelle (LLMs) bieten Anwender:innen von Sprachtechnologielösungen eine Vielzahl von Optimierungsmöglichkeiten. Im Vortrag zeigen wir Integrationsmöglichkeiten anhand konkreter Beispiele mit den Schwerpunkten Terminologie und Qualitätssicherung.
Bessere Benutzererfahrung und mehr Produktivität durch semantische Produktinformationen
Lernen Sie das leistungsstarke semantische Component Content Management von GRIPS kennen und wie es Inhalte präzise auf Benutzeranforderungen und Produktvariationen zuschneidet.
Einfach bessere Texte mit STAR GRIPS und Congree UCC
STAR und Congree präsentieren die neue STAR GRIPS-Schnittstelle: Entdecken Sie, wie Congree-Funktionen die Textqualität in Echtzeit sichern und durch moderne KI-Technologie die Effizienz Ihrer Texterstellung steigern.
Posted on: August 1st, 2024 by Frank Wöhrle No Comments
In der schnelllebigen Welt der Übersetzungs- und Lokalisierungsindustrie ist Effizienz der Schlüssel zum Erfolg. Eine Lösung, die dabei eine wichtige Rolle spielen kann, ist der Common Translation Interface (COTI) Standard, insbesondere in seiner hochentwickelten Form als COTI Level 3. Aber was genau verbirgt sich hinter diesem Standard und wie kann er Übersetzungsprozesse beschleunigen?
Was ist der COTI-Standard?
Der Common Translation Interface (COTI) Standard wurde speziell für die Übersetzungs- und Lokalisierungsindustrie entwickelt, um die Interoperabilität zwischen verschiedenen Softwaretools und Systemen zu verbessern. Der COTI-Standard definiert ein herstellerunabhängiges Format für den Austausch von Daten zwischen Translation Memory Systemen (TMS) und Redaktionssystemen, wie Content Management Systemen (CMS) und anderen Tools, die in der Branche verwendet werden.
Höherer COTI-Level, höhere Automatisierung
COTI Levels bauen aufeinander auf und bieten verschiedene Stufen der Integration und Automatisierung:
Level 1 – Core Features: Übersetzungsdaten werden in einer definierten Struktur gespeichert, als ZIP-Datei mit der Endung .coti komprimiert und mit Meta-Informationen angereichert. Der Datenaustausch erfolgt manuell, doch durch die Meta-Informationen und fixe Struktur lassen sich die Pakete vom empfangenden System leicht interpretieren.
Level 2 – Extended Features: Hier wird der Transfer der COTI-Datenpakete automatisiert. Das Redaktionssystem erzeugt ein Paket, das automatisch von einem TMS erkannt und importiert wird, sobald es in einen gemeinsamen Austauschordner (Hotfolder) gelegt wird, der permanent überwacht wird. Meta-Informationen ermöglichen dem empfangenden System beispielsweise eine automatisierte Auftrags-Anlage.
Level 3 – Expert Features: Die höchste Stufe der Integration bietet eine vollautomatisierte Datenübertragung zwischen den Systemen. Es ist keine manuelle Erstellung oder Überwachung von Paketen mehr nötig. Stattdessen erfolgt der Austausch von Übersetzungsdaten und Meta-Informationen über eine API-Schnittstelle zwischen Redaktionssystem und TMS. Neben den Übersetzungsdaten können so auch Statusinformationen wie z.B. der Übersetzungsfortschritt übermittelt werden.
Vorteile der Vollautomatisierung mit COTI Level 3
Die Implementierung von COTI Level 3 bringt zahlreiche Vorteile mit sich, die den Übersetzungsprozess erheblich verbessern können:
Schneller Datenaustausch: Durch die vollautomatisierte API-Schnittstelle werden Übersetzungsdaten nahtlos und ohne Verzögerungen zwischen Systemen ausgetauscht.
Effizienzsteigerung: Große und komplexe Übersetzungsprojekte können effizienter bearbeitet werden, da keine manuellen Schritte mehr erforderlich sind.
Rund-um-die-Uhr-Betrieb: Die Automatisierung ermöglicht einen kontinuierlichen Betrieb ohne menschliche Intervention, was zu einer rund-um-die-Uhr-Verfügbarkeit der Übersetzungsdaten führt.
Sicherheit: Durch die Eliminierung manueller Schritte wird das Risiko menschlicher Fehler minimiert, was einen sichereren Datenaustausch gewährleistet.
Zeit- und Kostenersparnis: Die Vollautomatisierung führt zu einer signifikanten Zeitersparnis und reduziert gleichzeitig den operativen Aufwand und die Kosten für Übersetzungsprojekte.
Fazit
Die Einführung von COTI Level 3 markierte einen bedeutenden Fortschritt in der Übersetzungsbranche, der nicht nur die Effizienz steigert, sondern auch die Qualität und Zuverlässigkeit der Übersetzungsprozesse verbessert. Durch die nahtlose Integration und automatisierte Datenübertragung können Unternehmen ihre globale Reichweite erweitern und gleichzeitig Zeit und Ressourcen sparen.
Aktuell können folgende Redaktionssyteme COTI-Pakete verschiedenster Levels ausspielen:
Mit dem Translation Memory-System STAR Transit NXT und unserer Workflow-Lösung STAR CLM bieten wir Ihnen Anbindungen auf allen 3 Levels, um optimal, sicher und schnell Daten auszutauschen und Übersetzungsprozesse zu beschleunigen.
Wir verarbeiten Ihre COTI-Pakete automatisiert mittels STAR CLM!
Posted on: April 18th, 2024 by Frank Wöhrle No Comments
Die perfekte Synergie für weltweit bessere Reichweite
Mehrsprachigkeit und SEO gehen Hand in Hand – wenn’s der Profi macht. STAR Deutschland und die netzgefährten laden Sie herzlich zu einer neuen Reise durch die SEO-Welt ein.
Zusammenspiel zwischen SEO und Mehrsprachigkeit, KI und Mensch
Erfahren Sie, worauf es bei Keywords und Content Creation ankommt, und wo die KI unterstützen kann! Das weltweit erfolgreiche Zusammenspiel von SEO und Übersetzung, KI und Mensch.
Kostenloses Webinar für geballtes SEO-Wissen
Das Webinar richtet sich an Mitarbeitende aus den Bereichen Marketing & Kommunikation, Produktmanagement und Vertrieb, die sich geballtes SEO-Wissen zu den Themen Keyword-Recherche und -Analyse sowie Content Creation wünschen. Die Teilnahme ist kostenfrei.
Posted on: März 11th, 2024 by Frank Wöhrle No Comments
Die sog. Large Language Models (LLMs) könnten zu einem starken Bindeglied zwischen Mensch und Maschine im Rahmen von Sprachprozessen werden.
Doch wo genau liegen die Vorteile dieser Technologie?
Dieser und weiteren wichtigen Fragen geht unser MT-Experte Julian Hamm im Rahmen des TechTalks „LLM Use Cases in Language Services“ von lingo systems nach und gewährt Einblicke in die Welt der Sprachtechnologien und CAT-Tool-Entwicklung.
Neugierig geworden?
STAR und lingo systems laden zum TechTalk ein
Sichern Sie sich jetzt Ihr kostenloses Ticket und seien Sie am 13.03.24 von 15 bis 16.30 Uhr live dabei. Der TechTalk findet auf Englisch statt.
Posted on: Februar 27th, 2024 by Frank Wöhrle No Comments
Kaum ein Wort hat das Jahr 2023 so geprägt wie „KI“. Doch was bedeutet dieses Buzzword eigentlich für Übersetzungs- und Sprachprozesse? Ist es nun an der Zeit, die noch relativ junge Technologie der neuronalen maschinellen Übersetzung (NMT) in den Ruhestand zu schicken und künftig voll und ganz auf große Sprachmodelle (LLMs) umzusteigen?
Tippst du noch oder prompst du schon?
Wie verändert sich dabei die Arbeit von professionellen Übersetzer*innen? Der Mensch am Steuer, die KI als Co-Pilot. Doch wie genau könnte das im Übersetzungsalltag aussehen? Das lernen Sie im Rahmen unseres einstündigen Webinars.
Chancen und Herausforderungen neuer Sprachtechnologien
Neben einer strategischen Herangehensweise an das sogenannte Prompt Engineering lernen Sie auch anhand praktischer Beispiele, wie CAT-Tools zukünftig aufgestellt sein müssen, um Sprachexpert*innen bei ihrer Arbeit optimal unterstützen zu können. Vorkenntnisse: Grundlegende Kenntnisse zum Umgang mit CAT-Tools und maschineller Übersetzung
MT-Expertise aus dem Hause STAR
Der Referent Julian Hamm, Übersetzer (M.A.), ist seit 2018 in der Sprachdienstleistungsbranche tätig. Bei der STAR Deutschland GmbH koordiniert er als Machine Translation Consultant die Umsetzung von MT-basierten Workflows und berät intern und extern rund um die spannenden Themen MT und Sprachtechnologien.
Der Mensch am Steuer, die KI als Co-Pilot – neugierig, was die Zukunft bereithält? Sichern Sie sich Ihren Platz für das tekom-Webinar unter Veranstaltungen (tekom.de) und steigen Sie am 14.03.24 um 16.30 Uhr ein.
Posted on: März 30th, 2022 by star_admin No Comments
Übersetzen mit Stift und Block? Wörterbücher schleppen und Terminologie-Listen ausdrucken? Wer sich bei diesem Gedanken ein wenig in die Studienzeit vor der Jahrtausendwende zurückversetzt fühlt, wird wahrscheinlich umso mehr spüren, wie sich der Übersetzungsprozess durch den Einsatz moderner Technologien bis dato verändert hat.
Die erste große Revolution stellten die immer potenter werdende Computerhardware und die damit einhergehenden Forschungen an automatisierten Übersetzungsworkflows dar. Der branchenweite Einsatz sogenannter CAT-Tools (Computer-Aided Translation), also Software, bei der bereits zuvor übersetzte Texte intelligent für Folgeprojekte wiederverwertet werden können, ließ nicht lange auf sich warten.
Mit der maschinellen Übersetzung wurde die zweite große Revolution eingeläutet. Grund also nun, den Menschen vor dem Computer nach Hause zu schicken und die Translatio ex machina zum Wundermittel zu erklären?
Wir meinen: Nein!
Denn wer maschinelle Übersetzung nachhaltig und effizient in bestehende Prozesse einbauen möchte, benötigt ein durchdachtes Qualitätssicherungskonzept, das nicht zuletzt die Arbeit unserer talentierten Sprachexpertinnen miteinschließt.
Beifall statt Unfall – wir zeigen Ihnen, worauf es ankommt!
Maschinelle Übersetzung (MT) im Arbeitsalltag
Der Einfluss von MT-Technologien auf das heutige Leben ist nicht zu leugnen. Mal ganz subtil im Hintergrund beim Scrollen durch ein Supportdokument, mal aktiv bei der Verwendung von Übersetzungssoftware zum Überwinden von Sprachbarrieren. Tagtäglich wachsen der Bedarf an Übersetzungen durch die zunehmende Globalisierung und das Bedürfnis der Menschen, Inhalte in ihrer eigenen Sprache zu konsumieren.
Dabei ergibt sich eine Vielzahl an Use Cases mit teilweise ganz unterschiedlichen Anforderungen – von der einfachen Informationsweitergabe zwischen Kolleginnen bis hin zu sprachlich und inhaltlich aufwendigen Texten für Zielmärkte mit anspruchsvoller Klientel.
Die Anforderungen an MT-Systeme sind hoch: mehr Content in weniger Zeit zu besseren Konditionen. Um hier mithalten zu können, ist gutes und nachhaltiges Training notwendig!
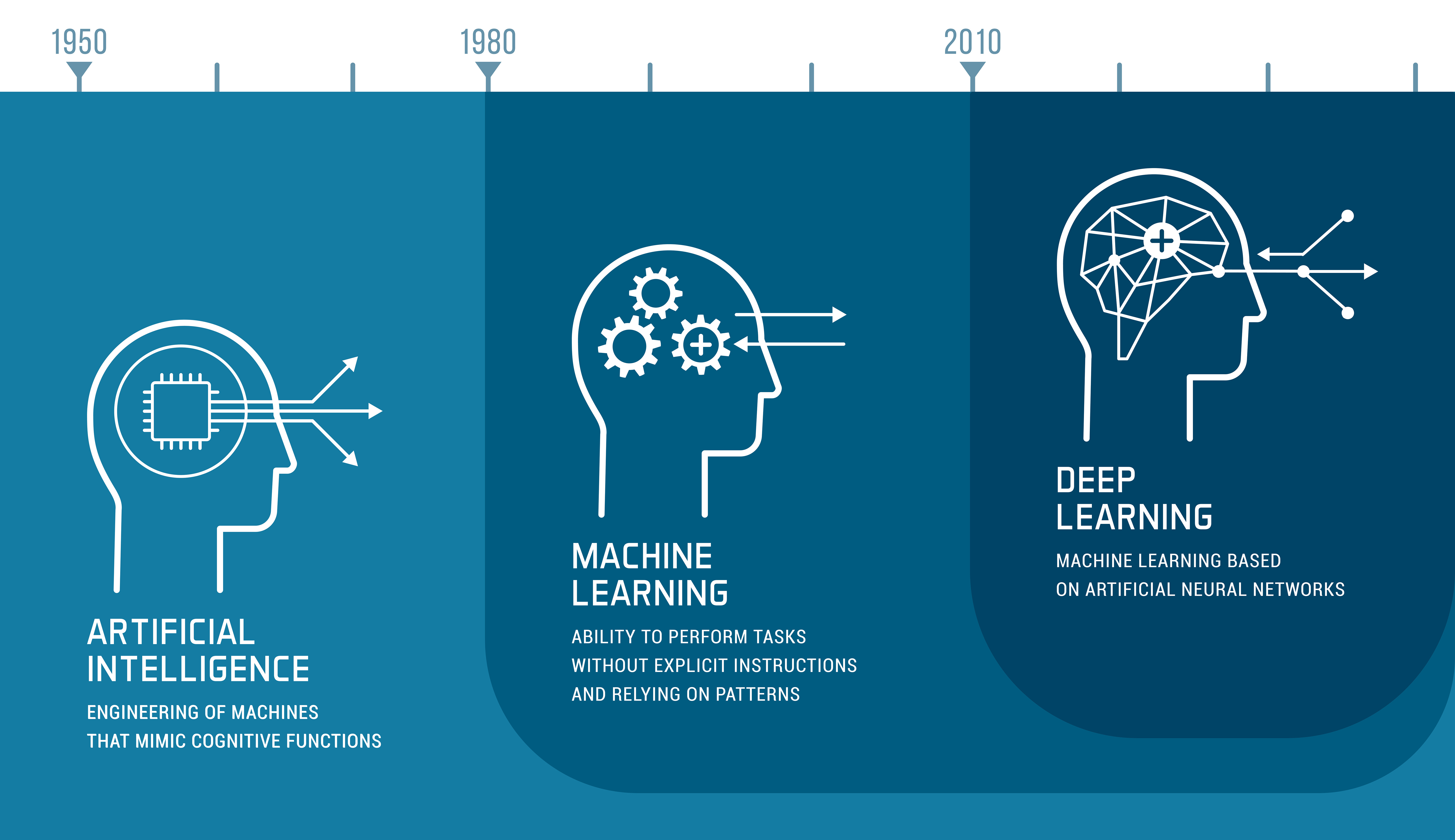
Artificial intelligence, machine learning and deep learning development infographic with icons and timeline
Gut trainiert ist halb gewonnen
Die Geschichte der MT geht zwar schon auf das 20. Jahrhundert zurück, doch erst in den letzten Jahren konnte sich durch die Fortschritte im Bereich der Sprachverarbeitung und des Deep Learning eine Technologie herauskristallisieren, die mit einer enormen Flexibilität und einem deutlichen Qualitätsvorsprung im Vergleich zu früheren Ansätzen aufwartet.
Bei diesen sogenannten neuronalen MT-Engines (NMT) werden zwei- oder mehrsprachige Textkorpora, die verifizierte Übersetzungen beinhalten, gesammelt, bereinigt und dann mit Hilfe von Deep-Learning-Algorithmen sprachliche Strukturen definiert. Durch mehrere Trainingsläufe werden die Ergebnisse überprüft und weiter perfektioniert. Dabei findet bei der NMT sogar eine Kontextualisierung der Informationen in Form von Wortclustern statt, über die das System entscheiden kann, mit welcher Wahrscheinlichkeit bestimmte Wortkombinationen in Erscheinung treten.
Verblüffend, nicht wahr? Aber auch nicht fehlerfrei!
Denn nicht zuletzt entscheidet vor allem die Qualität des verwendeten Trainingsmaterials über den MT-Output.
Enthalten Ihre Texte falsche Terminologie, Inkonsistenzen oder Bezugsfehler? Dann wird die MT-Engine diese Fehler mit großer Wahrscheinlichkeit ebenfalls produzieren.
Checkliste
Wir führen Sie Schritt für Schritt durch die wichtigsten Fragestellungen in Bezug auf die Einführung einer MT-Lösung.
Möchten Sie maschinelle Übersetzung effizient und nachhaltig einsetzen? Erfahren Sie mehr in unserem Whitepaper. Wir unterstützen Sie bei der Implementierung der passenden Lösung.
Mehr Informationen zum Thema Maschinelle Übersetzung
Posted on: November 23rd, 2020 by Yannick Beringer No Comments
STAR proudly presents: Unsere Kolleginnen Birgit M. Hoppe und Birgitta Geischberg tragen mit ihrem Artikel „Quality of terminology processes in corporate contexts / Agreeing and harmonizing terminology” zum soeben erschienenen Werk von Jean-Marc Dalla-Zuanna und Dr. Christopher Kurz bei.
Das Zeitalter der digitalen Transformation stellt uns vor die Herausforderung, den schwammigen Begriff der Übersetzungsqualität in eine Welt zu transportieren, die von Termini wie Schlüsselzahlen, künstliche Intelligenz und Automatisierung beherrscht wird. Beinahe täglich sehen wir uns mit einer Neudefinition unseres Berufs und unserer Arbeitsumgebung konfrontiert.
Der neue BDÜ-Sammelband ist ein mutiger und gelungener Ansatz, etwas Ordnung ins System zu bringen und stellt eine starke Verbindung zwischen Theorie und Praxis dar. Einerseits spiegelt das Buch Erkenntnisse, Tipps, Strategien und Anregungen aus der täglichen Arbeit wider, andererseits geht es auch auf theoretische Grundlagen ein und bietet einen facettenreichen Einstieg in das Themenfeld Qualität und Übersetzung, der zum Nachdenken anregt.
Behandelt werden u.a. die Fragenkomplexe Dimensionen der Übersetzungsqualität; Faktoren, die die Übersetzungsqualität maßgeblich beeinflussen; Bedeutung der Elemente des Übersetzungsökosystems für das Erreichen von Übersetzungsqualität sowie Anwendung in der Praxis: https://www.bdue-fachverlag.de/detail_book/150
Aus dem gesonderten Teil des 550 Seiten starken Werkes, der sich mit Faktoren befasst, die die Übersetzungsqualität maßgeblich beeinflussen, sei insbesondere das Schlagwort Terminologieverwaltung genannt. Obwohl überaus wichtig, wird die Bedeutung von einheitlicher und gut verwalteter Unternehmensterminologie immer wieder verkannt.
Posted on: Februar 11th, 2020 by Yannick Beringer No Comments
Ab sofort steht die standardisierte und herstellerübergreifende Referenzterminologie für die Automotive-Branche bereit. Sie entstand im Rahmen eines EU-Projekts mit dem Ziel, so genannten „berechtigten Dritten“ (unabhängigen Werkstätten, Prüfinstituten usw.) den Zugang zu Reparatur- und Wartungsinformationen (RMI) der Fahrzeughersteller zu erleichtern (Norm EN ISO 18542).
Als zentraler Partner verantwortete die STAR Group die Bereitstellung des initialen Datenbestands, stellte den Terminologiemanager und übernahm einen großen Teil des Projektmanagements. In enger Abstimmung mit Experten von Automobilherstellern und berechtigten Dritten wurden suchrelevante englische Terme identifiziert, validiert und in die Sprachen Deutsch und Französisch übersetzt. Für die kollaborative Erstellung und Pflege implementierte die STAR Group eine zentrale, webbasierte Workflow-Lösung, die auf WebTerm 7 (Terminologie-Management) und STAR CLM (Corporate Language Management) basiert.
Ziel war nicht die Sammlung möglichst vieler, sondern möglichst passender Begriffe, die das gesamte Fahrzeug abbilden. Die digitale Referenzterminologie enthält derzeit 521 detaillierte Datensätze in drei Sprachen und ist ab sofort beim Kooperationspartner DIN Software GmbH verfügbar. Mehr Informationen: https://www.dinsoftware.de/de/dienstleistungen/ra-rmi
Nach der initialen Veröffentlichung arbeiten die Experten bereits wieder an der Terminologie: Sie wird jährlich um aktuelle Begriffe für alle Fahrzeugklassen erweitert, als Schwerpunkt für 2020 ist der Bereich „Schwere Nutzfahrzeuge“ geplant. Das System und die Datenstruktur sind so ausgelegt, dass zusätzliche Bereiche der Norm EN ISO 18542 (z.B. für Motorräder und landwirtschaftliche Fahrzeuge) sowie weitere Sprachen problemlos abgebildet werden können. Damit bietet die neue digitale Terminologie auch langfristig interessante Perspektiven für die Nutzer.